

If you have been following deep learning trends, you may have noticed the hype surrounding Mamba. It is being promoted as a potential successor to Transformers, providing linear time complexity instead of the troublesome quadratic attention mechanism. But here’s the thing: when it comes to computer vision, pure Mamba models have been struggling to keep up with Transformers and even hybrid CNN-Transformer architectures.
Today, we’ll go through a paper (MambaVision: A Hybrid Mamba-Transformer Vision Backbone by Hatamizadeh and Kautz) that might just change that narrative.
MambaVision introduces the first successful hybrid Mamba-Transformer architecture designed explicitly for vision tasks, and it absolutely crushes the competition in terms of both accuracy and throughput on ImageNet-1K.
Let’s see how the researchers pulled it off!
The Transformer Dilemma
Let’s set the stage. Transformers have been the go-to architecture for pretty much everything: natural language processing, computer vision, speech processing, you name it. The attention mechanism is incredibly powerful because it can capture long-range dependencies in data.
If you haven’t worked with Transformers before, here’s the 30-second explanation of attention: it’s a mechanism that computes relationships between all parts of an input simultaneously. For each element (word, image patch, whatever), attention calculates how relevant every other element is, then uses those relevance scores to create a weighted combination of information. Every element can directly connect to every other element in one shot. That’s why attention excels at long-range dependencies. A pixel in the top-left corner can directly interact with a pixel in the bottom-right corner without going through a chain of intermediate steps.
But there’s a catch. The attention mechanism has quadratic complexity with respect to sequence length. For an input sequence of length n, the attention computation is:
$$Attention(Q,K,V) = Softmax\left(\frac{QK^T}{\sqrt{d_h}}\right)V$$
where \(Q\), \(K\), and \(V\) are the query, key, and value matrices, and \(d_h\) is the number of attention heads. The \(QK^t\) operation requires \(O\left(n^2\right)\) computations, which gets expensive real quick for high resolution images.
Enter Mamba, the Linear Time Alternative
Mamba came along and said, “Hey, what if we use State Space Models (SSMs) instead?” SSMs can process sequences in linear time, which sounds amazing. But translating this to vision tasks? That’s where things get tricky.
Here’s why pure Mamba struggles with vision.
1. Sequential Processing Isn’t Natural for Images
Text is sequential. Images aren’t. Word order changes meaning. “Dog bites man” isn’t the same as “man bites dog.” Pixel order is arbitrary. Images are about spatial relationships, not sequential ones.
2. Limited Global Context
Mamba looks at images sequentially, which is fundamentally at odds with how vision actually works. You need to see everything at once to understand spatial relationships. Mamba can’t do that in one shot.
Models like Vision Mamba (Vim) tried to fix this with bidirectional SSMs, but that introduced significant latency and training challenges. The result? Transformers and CNN-based backbones still outperformed Mamba-based models on most vision benchmarks.
The MambaVision Solution
The researchers behind MambaVision took a step back and asked: What if we don’t have to choose between Mamba and Transformers? What if we strategically combine both?

Their idea: use Mamba blocks for efficient sequence processing in earlier layers, then switch to self-attention blocks in the final layers to recover global context and capture long-range spatial dependencies.
Think of it like reading a book to understand the plot. Mamba reads page by page, building up context as it goes. It’s efficient at processing each page and remembering recent details. But Transformers? They can flip through the whole book, see how chapter 1 connects to chapter 20, and understand the overarching themes all at once. MambaVision does both. It reads efficiently page by page (Mamba), then steps back to see how everything connects (Transformers).
The Architecture Behind MambaVision
MambaVision uses a hierarchical architecture with 4 stages (Figure 2, page 3).
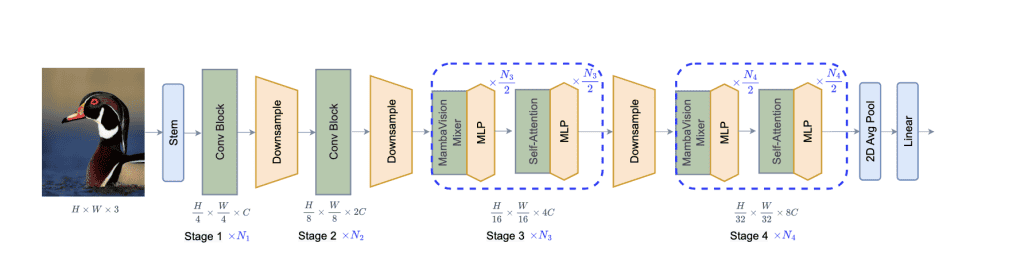
Stages 1 & 2: Fast CNN-Based Feature Extraction
The first two stages use convolutional neural networks (CNNs). Why? Because CNNs are incredibly efficient at processing higher-resolution features.
Starting with an input image of size \( H \times W \times 3 \), the stem converts it into overlapping patches of size \(\frac{H}{4} \times \frac{W}{4} \times C\) using two consecutive 3×3 CNN layers with stride 2.
The residual blocks in stages 1 and 2 follow this formulation:
$$\hat{z} = GELU\left(BN\left(\text{Conv}_{3\times3}\left(z\right)\right)\right)$$ $$z = BN\left(\text{Conv}_{3\times3}\left(\hat{z}\right)\right)+z$$
where GELU is the Gaussian Error Linear Unit activation function and BN is batch normalization.
Stages 3 & 4: The Hybrid Magic
This is where things get interesting. Stages 3 and 4 combine both MambaVision Mixer blocks and Transformer blocks.
For \(N\) total layers in these stages, the structure is:
- The first \(\frac{N}{2}\) layers: Mambavision Mixer blocks
- Last \(\frac{N}{2}\) layers: Self-attention (Transformer) blocks
Each layer follows this pattern:
$$\hat{X}^n=\text{Mixer}\left(\text{Norm}\left(X^{n-1}\right)\right)+X^{n-1}$$ $$X^n =\text{MLP}\left(\text{Norm}\left(\hat{X}^n\right)\right)+X^n$$
where the Mixer can be either a MambaVision Mixer or a self-attention block (page 4, Equation 6).
The MambaVision Mixer: Redesigning Mamba for Vision
Let’s walk through how the researchers redesigned the Mamba architecture specifically for vision tasks.
Quick Mamba Refresher
Standard Mamba transforms a 1D input \(x(t)\) into output \(y\left(t\right)\) via a hidden state \(h\left(t\right)\) with these equations: $$h’\left(t\right) = Ah\left(t\right) + Bx\left(t\right)$$ $$y\left(t\right) = Ch\left(t\right)$$
where \(A \in \mathbb{R}^{M\times M}, B \in \mathbb{R}^{M\times1}, \text{ and } C \in \mathbb{R}^{1\times M}\) are learnable parameters (page 3, Equation 2).
These continuous parameters are discretized for computational efficiency using a timescale \(\Delta \): $$\bar{A} = exp\left(\Delta A\right)$$ $$\bar{B} = \left(\Delta A\right)^{-1}\left(exp\left(\Delta A\right) – I\right) \cdot \left(\Delta B\right)$$ $$\bar{C} = C$$
The cool part about Mamba is its selection mechanism, which makes parameters \(B, C, \text{ and } \Delta \) input-dependent, allowing the model to filter out irrelevant information dynamically.
MambaVision Mixer Improvements
The authors made three key modifications to make Mamba more vision-friendly.
1. Replace Causal Convolution with Regular Convolution
The original Mamba uses causal convolution, which limits influence to one direction. This makes sense for text (left-to-right reading) but is unnecessarily restrictive for images. MambaVision uses regular 1D convolution instead.
2. Add a Symmetric Branch Without SSM
This is brilliant! They added a parallel branch that consists of just convolution and SiLU activation, without any SSM processing. This compensates for any spatial context lost due to the sequential constraints of SSMs.
3. Concatenate Instead of Gate
Instead of using a gating mechanism, they concatenate the outputs from both branches and project through a final linear layer.
Given an input \(X_{in}\), the MambaVision Mixer computes:
$$X_1=\text{Scan}\left(\delta\left(\text{Conv}\left(\text{Linear}\left(C,\frac{C}{2}\right)\left(X_{in}\right)\right)\right)\right)$$ $$X_2=\delta\left(\text{Conv}\left(\text{Linear}\left(C,\frac{C}{2}\right)\left(X_{in}\right)\right)\right)$$ $$X_{\text{out}} = Linear\left(\frac{C}{2}, C\right)\left(\text{Concat}\left(X_1,X_2\right)\right)$$
where Scan is the selective scan operation from Mamba, \(\delta\) is SiLU activation, and each branch projects to an embedding space of size \(\frac{C}{2}\).
Here’s the PyTorch-style pseudocode from the paper (Algorithm 1, page 4).
class MambaVisionMixer(nn.Module):
def __init__(self, dim, d_state=16, kernel_size=3):
super().__init__()
self.d_state = d_state
self.dt_rank = math.ceil(dim / 16)
self.in_proj = nn.Linear(dim, dim)
self.x_proj = nn.Linear(dim//2, self.dt_rank + self.d_state * 2)
self.conv1d_x = nn.Conv1d(dim//2, dim//2, kernel_size=kernel_size,
padding='same', groups=dim//2)
self.conv1d_z = nn.Conv1d(dim//2, dim//2, kernel_size=kernel_size,
padding='same', groups=dim//2)
self.dt_proj = nn.Linear(self.dt_rank, dim//2)
self.A_log = nn.Parameter(torch.log(repeat(torch.arange(1, self.d_state + 1),
'n -> d n', d=dim//2)))
self.D = nn.Parameter(torch.ones(dim//2))
self.out_proj = nn.Linear(dim, dim)
def forward(self, hidden_states):
xz = rearrange(self.in_proj(hidden_states), 'b l d -> b d l')
x, z = xz.chunk(2, dim=1) # Split into two branches
A = -torch.exp(self.A_log)
# Process both branches
x = F.silu(self.conv1d_x(x))
z = F.silu(self.conv1d_z(z))
# SSM processing on x branch
x_ssm = selective_scan_fn(x, dt, A, B, C, D)
# Concatenate and project
hidden_states = rearrange(torch.cat([x_ssm, z], dim=1), 'b d l -> b l d')
return self.out_proj(hidden_states)The main idea is that this combination ensures the final feature representation incorporates both sequential information (from the SSM branch) and spatial information (from the symmetric branch), leveraging the strengths of both approaches.
The researchers validated each design choice systematically. Starting from vanilla Mamba at 80.5% ImageNet accuracy, they measured the impact of each modification:
- Regular conv (not causal): +0.4% → 80.9%
- Add symmetric branch: +0.4% → 81.3%
- Concatenate instead of gate: +1.0% → 82.3%
Every change helped across all tasks (classification, detection, segmentation). The final design wasn’t a lucky guess – each architectural decision was empirically justified (Table 4, page 8).
Why Put Self-Attention at the End?
The researchers conducted a comprehensive ablation study (systematically testing different design choices) to find the optimal hybrid pattern. They tested several configurations and measured performance using Top-1 accuracy on ImageNet.
| Pattern | Layout | Accuracy |
| Random | Self-attention scattered randomly | 81.3% |
| First \(\frac{N}{2}\) Layers | SSSS MMMM | 81.5% |
| Alternating Self-attention and Mamba blocks | SMSM SMSM | 81.4% |
| Last \(\frac{N}{4}\) Layers | MMMMMM SS | 81.9% |
| Last \(\frac{N}{2}\) Layers | MMMM SSSS | 82.3% ✨ |
The best performance came from placing self-attention blocks in the final half of stages 3 and 4. Why does this work so well?
Think about it: the earlier Mamba layers efficiently process local spatial relationships and build up feature representations. Then, when the spatial resolution is lower (14×14 and 7×7 in stages 3 and 4), the self-attention blocks can affordably capture global context without the quadratic complexity explosion that would happen at higher resolutions.
You get Mamba’s efficiency for the heavy lifting and Transformer’s global reasoning for the final understanding!
The Results Are In: MambaVision Crushes It 💪🏾
Let’s talk numbers. MambaVision achieves state-of-the-art results across the board.
The researchers created several MambaVision variants of different sizes (T=Tiny, S=Small, B=Base, L=Large). Larger models have more parameters and higher accuracy but slower throughput. The ImageNet-1K results are below.
- MambaVision-T: 82.3% Top-1 accuracy with 6,298 images/sec throughput
- MambaVision-B: 84.2% Top-1 accuracy with 3,670 images/sec throughput
- MambaVision-L: 85.0% Top-1 accuracy with 2,190 images/sec throughput
Compare that to competitors:
- ConvNeXt-B: 83.8% accuracy with 1,485 images/sec
- Swim-B: 83.5% accuracy with 1,674 images/sec
- VMamba-B: 83.9% accuracy with 645 images/sec
Notice how MambaVision-B achieves higher accuracy than VMamba-B while being 5.7x faster. That’s the power of the hybrid approach.
Object Detection and Instance Segmentation (MS COCO)
ImageNet classification is great for benchmarking, but practical computer vision applications need more than just “what’s in this image?”
Not only does MambaVision excel at image classification, but it also works great as a backbone for more complex vision tasks. Object detection means finding and localizing all objects in an image (drawing bounding boxes around them). Instance segmentation goes further by outlining the exact pixel-level boundaries of each object.
Using Cascade Mask R-CNN, MambaVision backbones outperform comparable models:
- MambaVision-T: 51.1 box AP, 44.3 mask AP
- vs ConvNeXt-T: +0.7 box AP, +0.6 mask AP
- vs vs Swin-T: +0.7 box AP, +0.6 mask AP
- MambaVision-B: 52.8 box AP, 45.7 mask AP
- vs ConvNeXt-B: +0.1 box AP, +0.1 mask AP
- vs Swin-B: +0.9 box AP, +0.7 mask AP
Semantic segmentation assigns a class label to every single pixel in an image (is this pixel part of a road? a tree? a building?). It’s crucial for applications like autonomous driving and medical imaging.
With UperNet, MambaVision shows strong improvements:
- MambaVision-T: 46.0 mIoU (+1.5 over Swin-T)
- MambaVision-S: 48.2 mIoU (+0.6 over Swin-S)
- MambaVision-B: 49.1 mIoU (+1.0 over Swin-B)
Scaling to ImageNet-21K: The Big Leagues 🏟️
It turns out that MambaVision is the first Mamba-based vision model to successfully scale to ImageNet-21K pretraining.
The results are impressive:
- MambaVision-B: 84.2% → 84.9% after 21K pretraining
- MambaVision-L: 85.0% → 86.1% after 21K pretraining
- MambaVision-L3 (739.6M parameters): 87.3% @ 256 resolution, 88.1% @ 512 resolution
This scalability is critical for real-world applications. It shows that the hybrid architecture doesn’t just work at smaller scales but can leverage massive datasets and model sizes effectively.
Visualizing what MambaVision Sees 👀
One of my favorite parts of the paper is the attention visualization (Figure 5, page 8, and Figure S.1, page 12). The researchers visualized what the self-attention layers focus on, and the results are pretty cool.
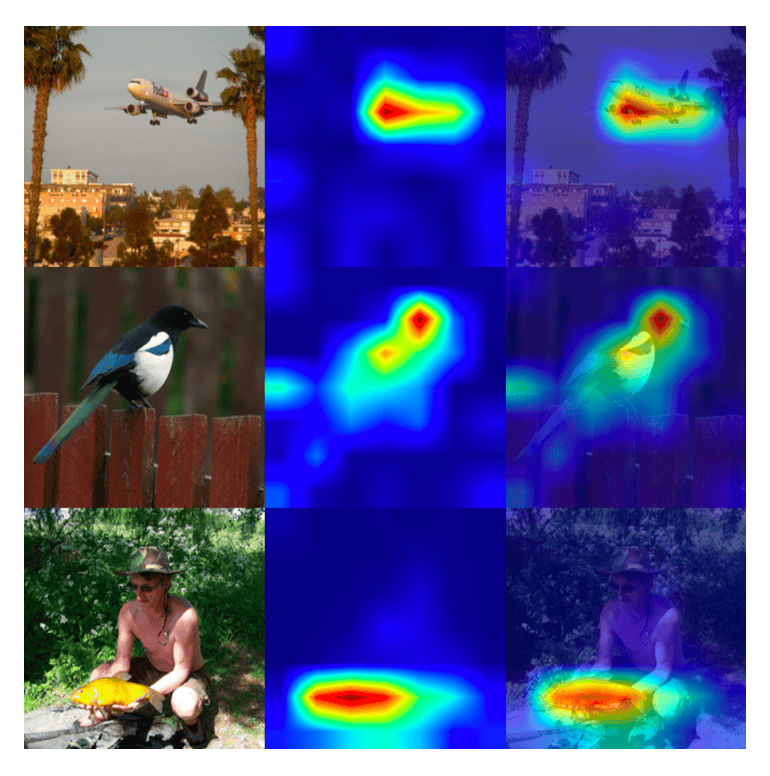
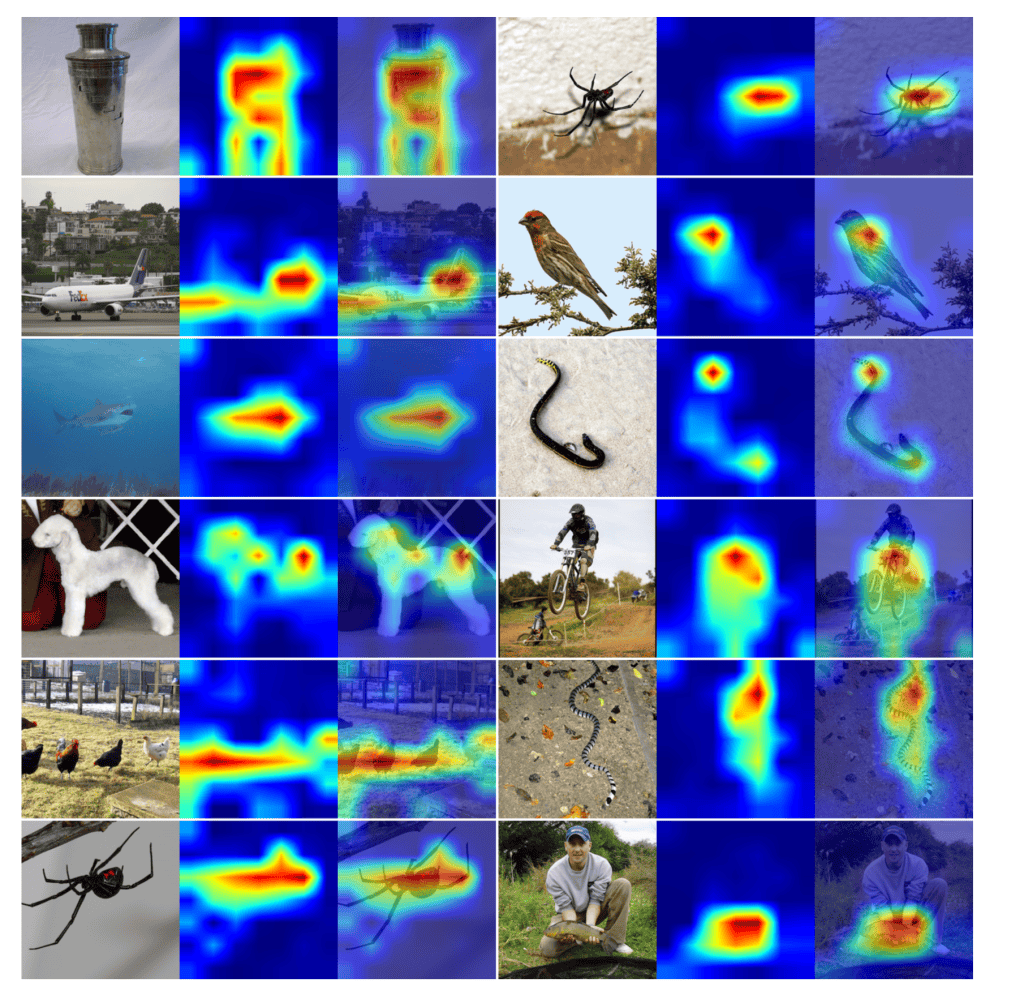
The attention maps show that MambaVision learns to:
- Focus on object boundaries: In an aircraft image, attention highlights the entire plane body
- Identify fine-grained details: For a bird, attention concentrates on distinctive features like the head and tail
- Model relationships: When showing a person holding an object, attention activates on both the subject and the object
This demonstrates that the self-attention layers are doing precisely what they’re supposed to do: capturing global context and understanding relationships between different parts of the image.
Practical Takeaways for ML Engineers
If you’re working on computer vision projects, here are some key lessons from MambaVision.
1. Hybrid Architectures Can Be Better Than Pure Approaches
Don’t feel like you have to choose between different architectures. Sometimes the best solution combines multiple approaches strategically. MambaVision shows that you can get the efficiency of SSMs and the global reasoning of Transformers in one model.
2. Architecture Placement Matters
Where you place different components in your network has a significant impact on performance. The ablation studies clearly show that putting self-attention in the final layers works much better than random or early placement.
3. Domain-Specific Modifications Are Worth It
The researchers didn’t just use Mamba as-is. They thoughtfully redesigned it for vision tasks by replacing causal convolutions and adding the symmetric branch. When adapting architectures from one domain to another, think about what makes sense for your specific problem.
4. Efficiency and Accuracy Aren’t Mutually Exclusive
MambaVision achieves both higher accuracy and better throughput than many competitors. This is possible through careful architectural design and understanding the computational characteristics of different operations.
5. Use CNNs for High-Resolution Processing
The paper uses CNNs in stages 1 and 2 for good reason. CNNs are still incredibly efficient at processing high-resolution features. Don’t overthink it; sometimes, the tried-and-true methods work best for certain tasks.
Implementation Tips
If you want to experiment with MambaVision-style architectures, here are some tips.
Start Small: Begin with the MambaVision-T configuration and scale up. The tiny version is much faster to train and iterate on.
Watch Your Window Sizes: The window size for self-attention matters. Use the ablation study as a guide (14 for stage 3, 7 for stage 4), but consider adjusting based on your specific task and input resolution.
Monitor Throughput: Don’t just track accuracy during training. Measure throughput too, especially if you’re planning to deploy the model in production. A 1% accuracy gain isn’t worth a 50% speed decrease in many applications 😱.
Leverage Pretrained Weights: The authors provide pretrained models on ImageNet-1K and ImageNet-21K. Start with these rather than training from scratch.
Consider Your Hardware: MambaVision was benchmarked on A100 GPUs. Performance characteristics might differ on other hardware, especially for the SSM operations.
The Bigger Picture
MambaVision represents an essential milestone in computer vision research. It’s the first successful hybrid Mamba-Transformer architecture and demonstrates that:
- Pure Mamba models aren’t inherently bad for vision; they just need help from self-attention to capture global context.
- Thoughtful architectural design can overcome the limitations of individual components.
- We’re not stuck choosing between efficiency (Mamba) and effectiveness (Transformers).
The field is moving toward more heterogeneous architectures that leverage the strength of different approaches. MambaVision is a great example of this trend, and I expect we’ll see more hybrid models in the future.
Getting Started with MambaVision
Want to try MambaVision yourself? The code is available at https://github.com/NVlabs/MambaVision.
Here’s how to get started:
pip install mambavisionimport torch
from mambavision import create_model
# Create model (loads pretrained weights)
model = create_model('mambavision_tiny', pretrained=True)
model.eval()
# Inference
image = torch.randn(1, 3, 224, 224) # Your image here
with torch.no_grad():
output = model(image)That’s it. The model returns ImageNet class predictions.
For fine-tuning on your own dataset, transfer learning to downstream tasks, or using MambaVision as a backbone for object detection, check they’re GitHub.
Conclusion
MambaVision achieves a new state-of-the-art Pareto front on ImageNet-1K, meaning it offers the best accuracy-throughput tradeoff available. The key innovations are:
- Redesigning the Mamba block for vision with regular convolutions and a symmetric branch.
- Strategically placing self-attention blocks in the final layers to recover global context.
- Using CNNs for efficient high-resolution feature extraction.
- Successfully scaling to large datasets and model sizes.
If you’re working on computer vision tasks, especially those that need both high accuracy and fast inference, MambaVision is definitely worth checking out.
The paper is available here, and the code is available here.
The hybrid architecture paradigm that MambaVision introduces might just be the template for the next generation of vision models. It shows that we don’t have to wait for the “perfect” architecture; sometimes the best solution is cleverly combining what we already have.
Now go forth and build some awesome vision models. Happy coding 🚀!
References: All page numbers refer to the MambaVision paper (arXiv:2407.08083v2)